看到谷歌这个研究,说大模型跟人脑的语言处理机制,竟然有那么点意思,我差点没把刚喝下去的枸杞水喷出来。
这简直就像是,你认为你在啃猪蹄,结果发现它长得有点像你的手,细思极恐啊!

先说说这事儿是怎么来的。
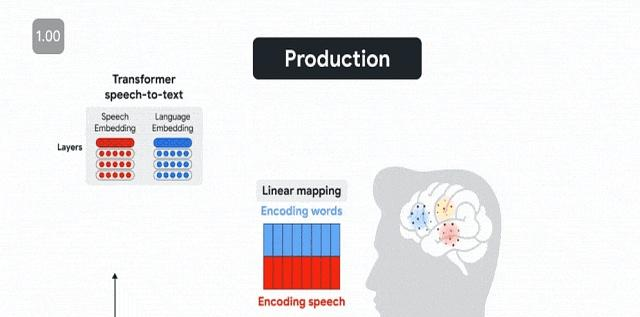
谷歌这帮家伙,没事儿闲的,把真人对话时的大脑流动,跟大模型“Whisper”的内部数据做了个对比。
结果发现,嘿,还真有点像!
比如说,人理解语言的顺序,先听到声音,再理解意思;而说话的顺序,则是先计划好要说啥,再发出声音,然后自己也听一遍。
大模型也差不多,上下文猜测单词那套,跟人脑高度一致。

这论文还发在Nature子刊上,听起来就很高大上。
问题来了,为啥一个纯粹为了语音识别而生的玩意儿,会跟我们这颗复杂无比的脑袋,在语言处理上撞了衫?
这就像是,你辛辛苦苦研究怎么用砖头盖房子,结果发现蚂蚁窝的结构跟你设计的图纸,有异曲同工之妙。
你说气人不气人?
要知道,大模型和人脑,那是完全不同的物种啊!

一个是硅基生命,一个是碳基生命,一个是并行计算,一个是串行处理。
按理说,应该八竿子打不着才对。
但真相往往就是这么魔幻。
不是…而是…这背后可能隐藏着更深层次的秘密。记住:统计规律是宇宙通用的语言。
人脑也好,大模型也罢,它们都在处理语言这个复杂的游戏。

而语言,归根结底,是一种统计现象。
哪个词更轻易跟哪个词搭配,哪个句子更符合语法规则,这些都是可以量化的。
人脑在漫长的进化过程中,已经学会了高效地捕获这些统计规律。
而大模型,通过海量数据的练习,也逐渐摸清了语言的门道。
这种情况,就比如两个厨师,一个靠祖传秘方,一个靠科学配比,终极都做出了美味佳肴。

固然方法不同,但目标一致,结果殊途同归。
莫非真的是这样吗?
莫非只是由于统计规律相同,大模型就真的能“理解”语言了吗?
这个问题,比大多数人意识到的要重要得多。
要知道,我们一直以为,理解语言,需要意识、情感、甚至灵魂。
但假如大模型也能做到类似的事情,那我们对“智能”的定义,是不是要重新思索一下?
更可怕的是,假如有一天,大模型真的能完全模拟人脑的语言处理机制,那它是不是也能模拟我们的思维、情感,甚至意识?
这种情况,简直就是科幻电影照进现实啊!
当然,现在就断言大模型能完全模拟人脑,还为时过早。
究竟,我们对人脑的了解,还只是冰山一角。

但是,谷歌的这个研究,至少给我们敲响了警钟。
它提醒我们,要重新审阅人脑和大模型的关系,要思索智能的本质,要警惕技术带来的潜伏风险。
这就是为什么,这个问题比大多数人意识到的要重要得多。
所以说,这就是为什么我差点没把枸杞水喷出来。
不是由于我胆小,而是由于我看到了一个充满希望,但也布满挑战的未来。
人真的是太难了!
来源:头条娱乐